开篇&MapReduce介绍及框架实现
Note. 现在分布式系统的架构设计已经成为后台开发者的必备技能,而Golang在并发方面引入了协程的方式,相对于其他语言极大地提高了并发处理能力。综合这些因素,麻省理工大学开设了用Golang实现分布式系统的课程,即6.824。在学习这门课程之前,最好对Golang有一定使用,不然在实现课程实验中会遇到较大的阻碍。而学习这门课程我们将涉及到存储、通信、计算等三方面的基础架构,目的是隐藏分布式复杂性的抽象。这些架构设计经验对于面试、工作也是非常有帮助的,希望接下来的分享能与大家探索分布式系统遇到的难题和乐趣。
1. 6.824课程开篇内容
下面简单罗列这个课程开篇的主要内容,包含课程目标、课程构成、实验介绍及主题。
为什么学习这门课程?
- 有趣,会遇到很多难题,但能提供非常强大的解决方案
- 被很多实际系统使用的理论知识,由大型网站的兴起驱动
- 活跃的研究领域,至今尚未解决的重要问题
- 动手操作,将在接下来的实验中构建真实的分布式系统
课程实验
- 实验1: MapReduce
- 实验2: 使用Raft共识算法实现容错
- 实验3: 实现具容错能力的key/value存储系统(基于实验2的实现)
- 实验4: 实现带有分片能力的key/value存储系统(基于实现3的实现)
课程主题
这是一门有关应用程序基础结构的课程:
- 存储
- 网络通信
- 计算
主题:动手实现,“纸上得来终觉浅,绝知此事要躬行”。
包括但不限于:RPC、多线程、并发控制、上面提到的4个实验。
主题:性能 目标:可扩展的吞吐量
Nx服务器->通过并行CPU,磁盘,网络达到Nx总吞吐量
当N增长时,扩展会变得越来越难:
负载不均衡、延迟取决于N机器里最慢的那一台
不可并行化的代码:初始化及交互
某些性能问题不能通过简单的扩展来解决
e.g 单个用户请求的快速响应时间
e.g 所有用户都想要更新相同的数据
通常需要更好的设计而不仅仅是添加更多的机器
主题:容错性
比如1000台服务器,组成的大网络 -> 这里面总会存在一些异常,比如机器挂掉或者网络出现分区
我们在实验中为用户隐藏这些错误的处理细节。
通常系统需要:
可用性 – 应用能够在发生错误的情况下继续提供服务
可恢复性 – 应用能够在错误恢复的时候马上恢复正常状态
整体思路:通过多份复制的服务器实现,如果有一台服务器挂掉,那么能够使用其他服务来处理这台服务器接受的请求
主题:一致性
通用基础结构需要明确定义的行为。
例如:”Get(k)会拿到Put(k,v)之后的最新值”
实现良好的行为很难!
“Replica”服务器很难保持一致。
客户端可能会在多步骤更新中崩溃。
服务端可能在执行之后但回复客户端之前崩溃。
网络分区可能会使存活的服务器看起来像宕机一样,有“脑裂”风险。
一致性和性能是矛盾的存在
强一致性需要节点间通信
许多设计仅提供弱一致性,以此来提高性能
下面以MapReduce作为第一个分布式系统案例来探讨可用性和一致性及分区容忍性之间的关系。
2. MapReduce介绍回顾
MapReduce的详细介绍可参考之前的文章MapReduce:大数据并行计算框架,本篇主要介绍MR框架的实验和代码细节,就不再赘述,核心围绕着MapReduce框架执行的整体流程来叙述。
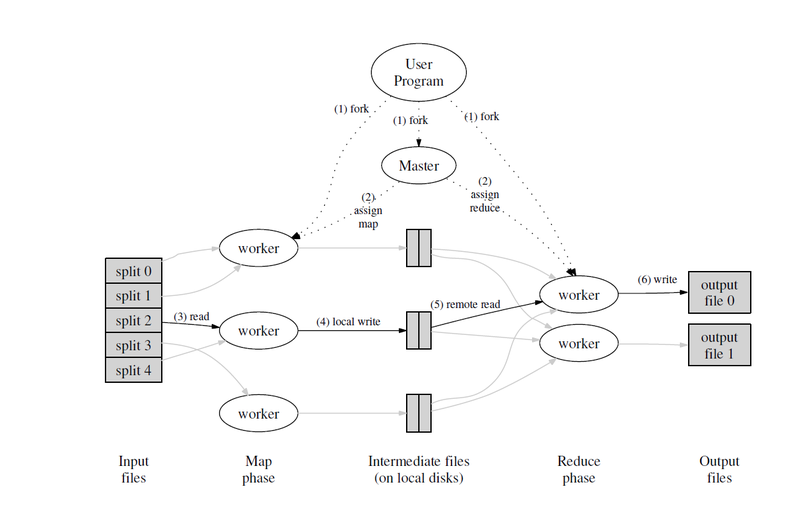
图 1 MapReduce框架执行流程
3. MapReduce课程框架介绍
这是一个构建MapReduce系统的实验[1],这个实验需要我们实现两个程序(以单个进程形式运行):
worker程序:调用应用程序定义的Map和Reduce函数,并通过读写文件方式来处理两个函数的输入、输出。
master程序:而master进程则负责将任务指派给worker,并处理执行过程中失败的worker。
可以看出MapReduce是一个典型的主从架构,接下来的实现如论文[2]所述。
环境准备
获取代码
$ git clone git://g.csail.mit.edu/6.824-golabs-2020 6.824
$ cd 6.824
$ ls
Makefile src
最开始实验里面已经包含了一个非分布式顺序执行的MapReduce实现,代码在src/main/mrsequential.go。这个程序以一个进程的方式运行,以顺序方式分别调用map和reduce函数,这里reduce函数一定是在执行完所有map函数之后才开始执行的。同时还提供了一些MapReduce应用,如mrapps/wc.go的统计单词数量程序。通过以下方式顺序执行:
$ cd ~/6.824
$ cd src/main
$ go build -buildmode=plugin ../mrapps/wc.go
$ rm mr-out*
$ go run mrsequential.go wc.so pg*.txt
$ more mr-out-0
A 509
ABOUT 2
ACT 8
...
执行mrsequential.go后,会把结果输出到文件mr-out-0,而输入来自pg-xxx.txt文件。
我们的分布式MapReduce框架整体流程也可直接借鉴非分布式的mrsequential.go代码。同时也看一下mrapps/wc.go,具体的MapReduce应用代码是怎样的,对于实现这个实验框架有很多启发。
实验任务
这次实验要实现一个分布式的MapReduce框架,由两个程序组成,分别为master和worker。运行过程中只会有一个master进程,而会有一个或多个worker进程同时运行。在现实系统中,worker程序会运行在不同的机器上,但是这个实验限定运行在单台机器上。worker与master之间通过RPC进行通信。每个worker进程会向master进程申请运行一个任务,期间会从一个或多个文件读取任务的输入,执行任务,并把任务的输出写入到一个或多个文件。master需要能够判断某个worker能否在一个合理的时间(这个实验限定为10秒)完成任务,如果不能完成的话将把任务重新分发给不同的worker。
下载的工程里面已经给出了框架整体代码。master和worker的”main”协程代码分别位于main/mrmaster.go及main/mrworker.go,请勿修改这两个文件。只需要修改mr/master.go、mr/worker.go、mr/rpc.go,在里面实现我们的逻辑即可。
下面是编译MapReduce应用的Golang插件及运行框架执行插件的流程:
$ go build -buildmode=plugin ../mrapps/wc.go
在main目录下,运行master
$ rm mr-out*
$ go run mrmaster.go pg-*.txt
pg-*.txt作为mrmaster.go的输入参数,每个文件对应的就是图1中的一份”split”,也是单个Map任务的输入。
在一个或多个terminal下运行worker:
$ go run mrworker.go wc.so
这个课程已提供了测试脚本main/test-mr.sh,当编写完代码时,运行脚本如果都能通过所有的case,就证明了我们的MapReduce框架是ok的。
$ sh ./test-mr.sh
*** Starting wc test.
--- wc test: PASS
*** Starting indexer test.
--- indexer test: PASS
*** Starting map parallelism test.
--- map parallelism test: PASS
*** Starting reduce parallelism test.
--- reduce parallelism test: PASS
*** Starting crash test.
--- crash test: PASS
*** PASSED ALL TESTS
$
实验要求:
-
map阶段需要把中间生成的key划分到
nReduce个reduce任务,实验main/mrmaster.go代码里把nReduce设定为10,作为参数传入到方法MakeMaster(); -
每个worker需要将第X个reduce任务的输出写入到文件
mr-out-X里; -
mr-out-X文件里每一行都是一个Reduce函数的输出。格式为key value,与main/mrsequential.go注释里”this is the correct format”部分要求相同。 -
只能修改
mr/worker.go、mr/master.go、mr/rpc.go这三个文件; -
worker进程需要把map阶段生成的中间输出写入到当前运行的目录,这样后面worker能在reduce阶段时候读入这些数据作为输入;
-
main/mrmaster.go里面调用mr/master.go的Done()方法,标记整个map、reduce任务是否已经完成从而退出; -
当整个map、reduce任务完成时,worker进程也需要结束掉。一种简单的方式是worker通过rpc主动向master进行查询,如果master返回结束,那worker就结束;如果与master间的通信失败了,也可以认为master已经结束提前退出,那么worker进程也可以退出了。
4. MapReduce框架逐步实现
在介绍完实验要求后,接下来就是实现的过程,其实课程介绍里已经给出以下思路提示,按照思路来coding就好了。
实验思路:
- 做这个实验最好的入手点是修改
mr/worker.go的Worker()方法,在方法里发送一个rpc请求到master申请执行一个任务。然后修改mr/master.go,master在接受到worker的申请执行任务请求后,为worker返回一个尚未开始的map或者reduce任务。worker收到请求回复后,根据任务类型,调用应用的Map或者Reduce函数,大致流程与mrsequential.go类似。
按照这个思路,我们可以定一个名为AskForTask()的rpc接口,参数其实不需要传递相关信息,接口返回值需要返回信息,告诉worker整个任务是否结束,未结束情况下该执行什么task类型,以及执行task需要的输入。如执行Map函数的话,需要告知Map的输入是哪个文件。还有当前Map或者Reduce任务的id,因此需要通过任务id编号来区分输入及输出,最后再返回整体Map及Reduce任务数量。
// 接口输入
type AskForTaskArgs struct {
}
// 接口输出
type AskForTaskReply struct {
CurPhase Phase
MapFile string
JobDone bool
MapNum int
ReduceNum int
MapTaskIdx int
ReduceTaskIdx int
}
// worker的rpc调用
func AskForTask() AskForTaskReply {
args := AskForTaskArgs{}
reply := AskForTaskReply{}
call("Master.AskForTask", &args, &reply) // rpc调用
return reply
}
worker根据返回值,选择退出或者执行Map、Reduce函数。
//
// main/mrworker.go calls this function.
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for { // 使用轮询的方式不断申请执行任务
reply := AskForTask() // 申请任务
if reply.JobDone { // 所有任务执行完毕,退出
break
}
switch reply.CurPhase {
case MapPhase:
// 执行Map任务
...
case ReducePhase:
// 执行Reduce任务
...
}
time.Sleep(time.Second) // 避免太多的忙轮询,这里选择sleep一秒,但是还是会浪费掉cpu以及不能及时的获取到任务进行执行,影响任务执行的总时间
}
}
上面就是worker的整体处理流程,在展开Map任务及Reduce任务处理细节前,实验里还给了以下几点提示:
-
由于这个实验的worker都是运行在同一台机器上,所以读写同一份文件系统即可。但是运行在不同机器上的时候,就需要一个GFS这样的分布式文件系统。
-
对于Map任务的中间输出一个比较合理的文件命名规范为:
mr-X-Y,其中X是Map任务的编号,Y是Reduce任务的编号。 -
worker处理Map任务的时候,需要将中间输出持久化,为了能让Reduce任务重新读取这些中间输出作为reduce阶段的输入,可以使用json进行序列化。处理Reduce任务的时候,进行反序列化再进行处理。
-
执行Map任务的时候,worker可以使用提供的
ihash(key)函数(在worker.go)为每一对中间key/value选择对应的Reduce任务去处理。这部分的逻辑可以借鉴mrsequential.go。里面包含读取Map的输入文件,对介于Map和Reduce阶段中间的key/value进行排序,并将Reduce结果写入到文件等代码。 -
考虑到master无法准确判断某个worker运行是否出现崩溃,比如有可能是网络原因导致worker运行完毕但是在通知master执行成功的时候失败等等。因此master需要为每个worker执行任务进行倒计时,这个实验限定了执行时间为10秒,超过这个时间后,master就可以认为worker已经出现异常,稍后重新将所执行的任务分发给其他worker。
-
另外为了防止worker运行中出现崩溃,导致写入的文件是不完整的,例如在处理Reduce任务的时候,每处理完一个key、value就写入到文件
mr-out-Y,但是在写入所有数据之前突然崩溃,那么这个mr-out-Y文件肯定是不完整。MapReduce论文提到了,使用临时文件写入结果再通过原子重命名方式来保证一旦mr-out-Y生成了,内容就是完整的。Golang的实现可参考[3],代码逻辑如下:oname := fmt.Sprintf("mr-out-%+v", reply.ReduceTaskIdx) uuidInstance := uuid.New() uuidFileName := fmt.Sprintf("mr-tmp-reduce-%v", uuidInstance.String()) ofile, err := os.OpenFile(uuidFileName, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644) ... fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output) // 写入到临时文件uuidFileName ... os.Rename(uuidFileName, oname) // 由操作系统保证原子性
worker的Map、Reduce任务执行逻辑
执行Map任务的时候,大致流程就是根据master返回的Map文件名读取文件内容,然后使用应用的mapf函数产生中间数据,再通过key计算出后续由哪个Reduce任务处理,最后以json等方式分别序列化到中间文件mr-X-Y。
switch reply.CurPhase {
case MapPhase:
// 执行Map任务
...
fileName := reply.MapFile
file, _ := os.Open(fileName)
content, _ := ioutil.ReadAll(file) // 读取map的输入
kva := mapf(fileName, string(content)) // 调用应用的map函数生成中间数据
mapPhaseSucc := true
for i := 0; i < len(kva); i++ {
reduceTaskIdx := ihash(kva[i].Key) % askForReply.ReduceNum // 计算key由后续哪个Reduce任务处理
intermediateEncoder := intermediateEncoderMap[reduceTaskIdx]
if err := intermediateEncoder.Encode(kva[i]); err != nil { // 序列化到临时文件
log.Fatalf("encode kv:%v failed", kva[i])
mapPhaseSucc = false
NotifyWorkerTaskStatus(MapPhase, askForReply.MapTaskIdx, Fail) // 调用rpc
,通知master执行过程中存在问题,任务执行失败
break
}
}
if mapPhaseSucc {
for reduceIdx, fileName := range intermediateFileNameMap {
os.Rename(fileName, fmt.Sprintf("mr-%+v-%+v", askForReply.MapTaskIdx, reduceIdx)) // 通过os的原子重命名,保证文件内容的完整性
}
NotifyWorkerTaskStatus(MapPhase, askForReply.MapTaskIdx, Success) // 通知master,任务执行成功
}
}
执行Reduce任务的时候,流程也类似。根据master分配的ReduceTaskIdx分别从mr-0-ReduceTaskIdx、…、mr-MapNum-ReduceTaskIdx读取输入并整合,对整合后的数据按照key进行排序。接着对每一个key,合并对应的value,再调用应用的reduce
函数生成最终结果,并把结果输出到文件。
case ReducePhase:
intermediate := []KeyValue{}
for i := 0; i < reply.MapNum; i++ {
fileName := fmt.Sprintf("mr-%+v-%+v", i, askForReply.ReduceTaskIdx) // 分别从所有的Map的输出读取当前Reduce任务需要处理的数据
file, _ := os.Open(fileName)
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
intermediate = append(intermediate, kv)
}
}
sort.Sort(ByKey(intermediate)) // 对整合后的数据按key排序
oname := fmt.Sprintf("mr-out-%+v", reply.ReduceTaskIdx) // Reduce任务的最终输出
uuidInstance := uuid.New()
uuidFileName := fmt.Sprintf("mr-tmp-reduce-%v", uuidInstance.String()) // 临时文件
ofile, _ := os.OpenFile(uuidFileName, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644)
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
// 对每一个key,合并对应的value
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values) // 调用应用reduce函数,生成
// this is the correct format for each line of Reduce output.
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
os.Rename(uuidFileName, oname) // 通过os的原子重命名,保证文件内容的完整性
NotifyWorkerTaskStatus(ReducePhase, askForReply.ReduceTaskIdx, Success) // 通知master,reduce任务执行成功
master的任务分发流程
前面已经描述完worker的任务执行过程,这一节将描述master的并发控制以及任务的分发、任务的超时和失败处理策略。
同样地,需要先设计好master的数据结构,因为master需要掌握全局的信息才能进行任务分发,所以至少要包含输入的文件、Map和Reduce任务的总数量,以及Map、Reduce任务执行情况等等信息。因此,大致结构如下:
const (
NotYetStarted TaskStatus = iota
Doing
Done
)
type Master struct {
// Your definitions here.
Files []string // 要处理的文件
MapNum int // Map任务总数
ReduceNum int // Reduce任务总数
MapTaskStatusMap []TaskStatus // Map任务执行状态,初始值都是未开始NotYetStarted
ReduceTaskStatusMap []TaskStatus // Reduce任务执行状态,初始值也都是未开始NotYetStarted
CurPhase Phase // 当前执行阶段,MapPhase还是ReducePhase
Finished bool // 整个job是否完成,以便让master退出,还有让worker退出
DoneMapNum int // 记录当前已完成的Map任务数量,决定是否要进入Reduce阶段
DoneReduceNum int // 记录当前已完成的Reduce任务数量,决定是否结束Reduce阶段,并标记整个job完成
}
接下来对master进行初始化:
// create a Master.
// main/mrmaster.go calls this function.
// nReduce is the number of reduce tasks to use.
//
func MakeMaster(files []string, nReduce int) *Master {
m := Master{}
// Your code here.
m.Files = files
m.MapNum = len(files)
m.ReduceNum = nReduce
m.DoneMapNum = 0
m.DoneReduceNum = 0
m.Finished = false
m.MapTaskStatusMap = make([]TaskStatus, len(files))
for i := 0; i < len(m.Files); i++ {
m.MapTaskStatusMap[i] = NotYetStarted
}
m.ReduceTaskStatusMap = make([]TaskStatus, nReduce)
for i := 0; i < nReduce; i++ {
m.ReduceTaskStatusMap[i] = NotYetStarted
}
m.server()
return &m
}
前面提到了AskForTask()的rpc接口的调用,下面是master的rpc接口实现,用于处理worker的申请任务请求。整体过程也是先判定job是否结束,未结束时候再根据当前执行阶段,分发尚未开始的Map任务或者Reduce任务。这里Reduce任务一定要在所有Map任务执行完毕后才会开始分发。同时也要考虑并发读取master数据,可以选择加锁等方式保证并发安全。
func (m *Master) AskForTask(args *AskForTaskArgs, reply *AskForTaskReply) error {
mutex.Lock() // 加锁,粒度比较粗
if m.Finished { // job已经处理完毕,通知worker退出
mutex.Unlock()
reply.JobDone = true
return nil
}
reply.JobDone = false
if m.CurPhase == MapPhase {
// 遍历Map任务状态,找到一个尚未开始的任务分发给worker
for i := 0; i < len(m.MapTaskStatusMap); i++ {
if m.MapTaskStatusMap[i] == NotYetStarted {
reply.MapFile = m.Files[i]
reply.CurPhase = MapPhase
reply.MapNum = m.MapNum
reply.ReduceNum = m.ReduceNum
reply.MapTaskIdx = i
m.MapTaskStatusMap[i] = Doing
go func(mapTaskIdx int) { // 这里需要为每个Map任务进行倒计时,一旦任务执行超过10秒,便标记未尚未开始,等待下次重新执行
timer := time.NewTimer(time.Second * 10)
<-timer.C
mutex.Lock()
if m.MapTaskStatusMap[mapTaskIdx] == Doing {
m.MapTaskStatusMap[mapTaskIdx] = NotYetStarted
}
mutex.Unlock()
}(i)
break
}
}
} else if m.CurPhase == ReducePhase {
// 与Map处理方式类似
...
}
mutex.Unlock() // 释放锁
return nil
}
前面提到了worker执行任务后,会调用NotifyWorkerTaskStatus这个rpc接口通知master任务执行状态,master再同步更新任务状态信息及当前执行阶段。
func (m *Master) NotifyWorkerTaskStatus(args *NotifyWorkerTaskStatusArgs, reply *NotifyWorkerTaskStatusReply) error {
mutex.Lock()
if args.WorkerPhase == MapPhase {
if args.Status == Success {
m.MapTaskStatusMap[args.TaskIdx] = Done // 标记任务状态为已完成
m.DoneMapNum++ // 已完成任务数量加一
if m.DoneMapNum == m.MapNum { // 所有任务已完成,则开始进入reduce阶段
m.CurPhase = ReducePhase
}
} else if args.Status == Fail {
m.MapTaskStatusMap[args.TaskIdx] = NotYetStarted // 失败情况下,重新标记为尚未开始,等待下一次调度
} else {
mutex.Unlock()
return fmt.Errorf("unknown task status:%+v phase:%+v taskIdx:%+v", args.Status, args.WorkerPhase, args.TaskIdx)
}
} else if args.WorkerPhase == ReducePhase {
// 与Map处理方式类似
...
if m.DoneReduceNum == m.ReduceNum { // 所有reduce任务已完成,标记整个job为完成状态,等待退出
m.Finished = true
}
...
}
mutex.Unlock()
return nil
}
最后master通过周期性地检查Finished标记,即可判定是否退出。
//
// main/mrmaster.go calls Done() periodically to find out
// if the entire job has finished.
//
func (m *Master) Done() bool {
ret := false
// Your code here.
mutex.Lock() // 保证并发安全
ret = m.Finished
mutex.Unlock()
return ret
}
使用测试脚本验证
整合上面的思路后,一个简单能work的MapReduce框架就出来了。
master完整代码详见:https://github.com/berryjam/6.824-2020/blob/master/src/mr/master.go
worker完整代码详见:https://github.com/berryjam/6.824-2020/blob/master/src/mr/worker.go
最后运行测试脚本test-mr.sh,如果最后输出PASSED ALL TESTS字样,那就说明所有test case都通过了: )
$ sh test-mr.sh
os.Args[2:] [../pg-being_ernest.txt ../pg-dorian_gray.txt ../pg-frankenstein.txt ../pg-grimm.txt ../pg-huckleberry_finn.txt ../pg-metamorphosis.txt ../pg-sherlock_holmes.txt ../pg-tom_sawyer.txt]
filename:../pg-being_ernest.txt
filename:../pg-dorian_gray.txt
filename:../pg-frankenstein.txt
filename:../pg-grimm.txt
filename:../pg-huckleberry_finn.txt
filename:../pg-metamorphosis.txt
filename:../pg-sherlock_holmes.txt
filename:../pg-tom_sawyer.txt
*** Starting wc test.
2020/09/14 15:55:01 rpc.Register: method "Done" has 1 input parameters; needs exactly three
--- wc test: PASS
os.Args[2:] [../pg-being_ernest.txt ../pg-dorian_gray.txt ../pg-frankenstein.txt ../pg-grimm.txt ../pg-huckleberry_finn.txt ../pg-metamorphosis.txt ../pg-sherlock_holmes.txt ../pg-tom_sawyer.txt]
filename:../pg-being_ernest.txt
filename:../pg-dorian_gray.txt
filename:../pg-frankenstein.txt
filename:../pg-grimm.txt
filename:../pg-huckleberry_finn.txt
filename:../pg-metamorphosis.txt
filename:../pg-sherlock_holmes.txt
filename:../pg-tom_sawyer.txt
*** Starting indexer test.
2020/09/14 15:55:14 rpc.Register: method "Done" has 1 input parameters; needs exactly three
--- indexer test: PASS
*** Starting map parallelism test.
2020/09/14 15:55:25 rpc.Register: method "Done" has 1 input parameters; needs exactly three
--- map parallelism test: PASS
*** Starting reduce parallelism test.
2020/09/14 15:55:40 rpc.Register: method "Done" has 1 input parameters; needs exactly three
--- reduce parallelism test: PASS
os.Args[2:] [../pg-being_ernest.txt ../pg-dorian_gray.txt ../pg-frankenstein.txt ../pg-grimm.txt ../pg-huckleberry_finn.txt ../pg-metamorphosis.txt ../pg-sherlock_holmes.txt ../pg-tom_sawyer.txt]
filename:../pg-being_ernest.txt
filename:../pg-dorian_gray.txt
filename:../pg-frankenstein.txt
filename:../pg-grimm.txt
filename:../pg-huckleberry_finn.txt
filename:../pg-metamorphosis.txt
filename:../pg-sherlock_holmes.txt
filename:../pg-tom_sawyer.txt
*** Starting crash test.
2020/09/14 15:55:57 rpc.Register: method "Done" has 1 input parameters; needs exactly three
--- crash test: PASS
*** PASSED ALL TESTS
这个实验是单机通过rpc方式来模拟分布式环境,实际跨节点的分布式环境会更复杂。单机环境的输入都来源同一节点上的文件系统,而分布式系统下输入及输出需要依赖分布式文件系统。而且本节实现只是一个比较简单的map reduce实现,比如master对于并发控制粒度比较粗,性能上还有很多优化的空间,不过这个实验本身还是很有趣,会遇到很多实际问题需要我们去解决让我们积累更多经验,反过来又会让我们设计出更可靠、性能更好的系统。生产级的分布式并行计算框架里面会涉及到更多的细节和优化,可谓道阻且长。
5. 参考资料
[1] 6.824 Lab 1: MapReduce
[2] MapReduce: Simplified Data Processing on Large Clusters
[3] atomic file writing